
ALFWorld
2020년에 작성된 ALFWorld 프로젝트의 논문을 보고 개인적으로 요약, 느낀점을 서술한 내용입니다. 잘못된 내용이 있다면 알려주시면 수정하겠습니다.
최근에 논문들은 러프하게 계속해서 읽고있었는데, 이후에 나오는 논문들에서 이전 논문들을 인용하는 경우가 많아 읽었던 논문들을 디테일하게 다시 읽어보고 내용을 정리해서 올려볼 예정입니다.
ALFWorld는 자연어를 통한 추상적 사고와 물리적 환경의 행동을 정렬(aligning)한 프로젝트입니다. 이렇게 말하면 굉장히 추상적인 개념이라 크게 와닿지 않을수있는데 아래 이미지를 보시면 바로 이해하실 수 있을겁니다.

왼쪽의 TextWorld와 Embodied의 실제 환경속에서 두 환경을 서로 일치시키는겁니다. ALFWorld에서는 BUTLER라는 에이전트를 설계하여 테스트를 진행하였습니다.
우선 벤치마크를 측정하기 위한 ALFRED 데이터셋은 아래와 같습니다.
| Task type | #train | #seen | #unseen |
|---|---|---|---|
| Pick & Place | 790 | 35 | 24 |
| Examine in Light | 308 | 13 | 18 |
| Clean & Place | 650 | 27 | 31 |
| Heat & Place | 459 | 16 | 23 |
| Cool & Place | 533 | 25 | 21 |
| Pick Two & Place | 813 | 24 | 17 |
| All | 3,553 | 140 | 134 |
여기서 중요한건 seen과 unseen부분인데, seen은 train과 유사한 환경이지만 객체의 위치나 수량, 배치와 같은것에 변형이 가해진 환경이고 unseen은 학습한 환경이랑은 다른 새로운 환경입니다.
BUTLER는 아래와 같이 구성되어있습니다.
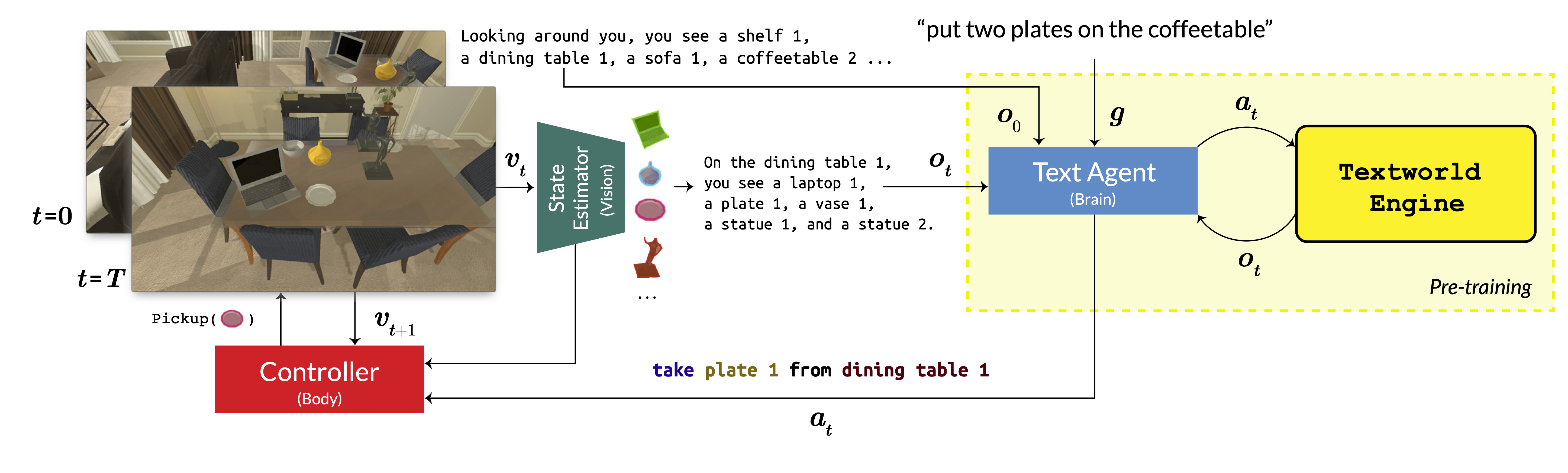
주의깊게 볼 부분은 BUTLER는 3개의 모듈(Vision, Brain, Body)로 구성되어 있습니다.
- Brain은 지금은 굉장히 친숙한 Transformer 기반으로 만들어져있습니다.
- Vision은 RCNN을 이용하여 실제 환경정보를 자연어로 변환합니다.
- Body는 로우레벨로 내려오는 행동을 수행하는 역할을 담당합니다.
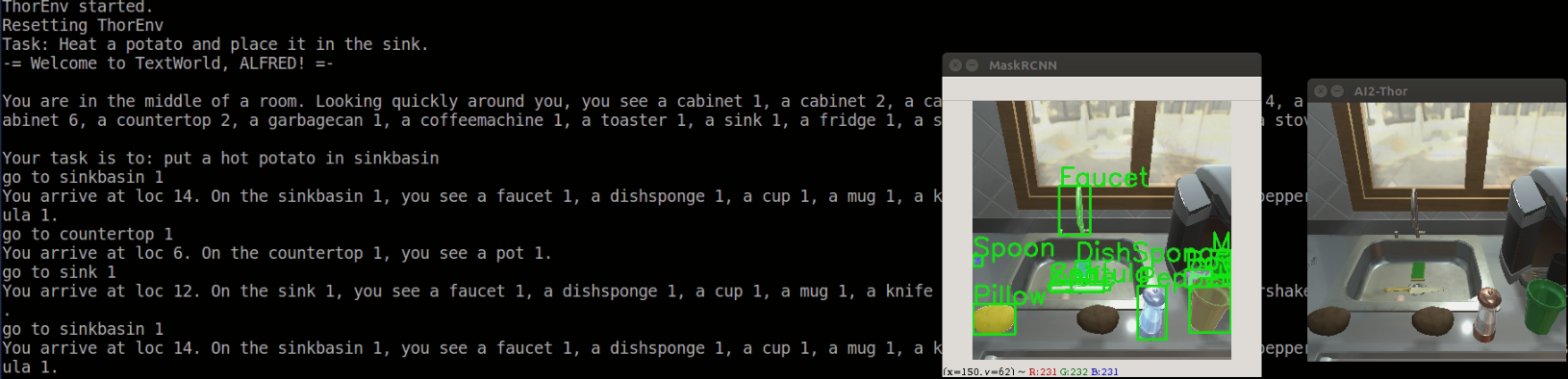 RCNN의 예시
RCNN의 예시
BUTLER의 플로우를 보면 알다시피 처음에 $g$(goal)이 주어지면 $t=0$부터 작업이 진행됩니다. $O_0$에서 현재 환경에 대한 전체적인 정보를 받고나면 이후부턴 t에 맞춰 현재 화면의 정보를 받고 Brain이 해당 정보를 토대로 학습된 정보를 토대로 Body에 $a_t$를 전달하면 Body가 해당 역할을 수행하는 방식입니다.
테스트 결과는 아래와 같습니다.
TextWorld
| task type | seen | unseen |
|---|---|---|
| Pick & Place | 69 | 50 |
| Examine in Light | 69 | 39 |
| Clean & Place | 67 | 74 |
| Heat & Place | 88 | 83 |
| Cool & Place | 76 | 91 |
| Pick Two & Place | 54 | 65 |
| All | 40 | 35 |
우선 TextWorld는 실제 환경없이 순수하게 Brain의 성능에 대한 결과입니다. 전체적으로 높은 성공률을 보이고 특히 학습하지않은 unseen에 대한 환경에서도 꽤 높은 수치를 보입니다.
Seq2Seq
| task type | seen | unseen |
|---|---|---|
| Pick & Place | 28(28) | 17(17) |
| Examine in Light | 5(13) | 0(6) |
| Clean & Place | 32(41) | 12(31) |
| Heat & Place | 10(29) | 12(33) |
| Cool & Place | 2(19) | 21(34) |
| Pick Two & Place | 12(23) | 0(26) |
| All | 6(15) | 5(14) |
일반적인 Seq2Seq의 성능은 위와 같습니다. 괄호의 영역은 전체적으로 수행하지 못했더라도 부분적으로 수행한 성공률을 의미합니다.
BUTLER
| task type | seen | unseen |
|---|---|---|
| Pick & Place | 30(30) | 24(24) |
| Examine in Light | 10(26) | 0(15) |
| Clean & Place | 32(46) | 22(39) |
| Heat & Place | 17(38) | 16(39) |
| Cool & Place | 5(21) | 19(33) |
| Pick Two & Place | 15(33) | 8(30) |
| All | 19(31) | 10(20) |
BUTLER는 전체적으로 Seq2Seq보다 더 높은 성공률을 보이는것도있지만, 더 중요하게 봐야할 부분은 학습된 seen의 환경에서의 변화가 아닌 unseen이라는 환경의 변화에도 굉장히 유의미한 차이가 보인다는걸 알수있습니다.
하지만 생각해보면 TextWorld는 앞서 말했듯이 BUTLER의 Brain모듈인데 왜 기존 BUTLER와 차이가 이렇게 크게 나는걸까요? 이는 BUTLER라는 에이전트는 여러가지의 모듈로 구성되어있고, Vision과 Body가 각각 RCNN에서 물체를 인식하지 못한다거나 액션의 피드백을 잘못받았을때의 간극이 존재하기때문에 TextWorld의 환경과는 다른 결과가 나왔습니다.
하지만 만약 이 환경조차 가장 이상적인 형태의 환경을 제공한다면 어떨까요?
BUTLER-ORACLE
| task type | seen | unseen |
|---|---|---|
| Pick & Place | 53(53) | 31(31) |
| Examine in Light | 22(41) | 12(37) |
| Clean & Place | 44(57) | 41(56) |
| Heat & Place | 60(66) | 60(72) |
| Cool & Place | 41(49) | 27(44) |
| Pick Two & Place | 32(42) | 29(44) |
| All | 37(46) | 26(37) |
BUTLER-ORACLE은 물체 감지에 ground-truth object detections를 사용하고 컨트롤러 또한 BUTLER는 A*로 움직이지만 텔레포트로 움직이는등 가장 이상적인 환경을 제공한 결과입니다. 이는 TextWorld와 아직까지는 차이가 있지만 굉장히 높은 성공률을 보입니다.
마치며
우리가 이 연구에서 얻을 수 있는 교훈은 뭘까요? 사실 지금와서는 이 논문에서 말하는 개념같은것들이 크게 와닿지 않을 수 있습니다. 지금 저희에게 있어서는 꽤 당연하게 느껴지는것들이 많기때문입니다.
Agent를 개발할때도 내부에 여러개의 레이어별로 복수의 Agent를 구현하여 사용한다거나 모듈화같은 개념은 이제는 너무나도 당연한게 되어버렸습니다.
하지만 이 논문이 2020년에 작성된것이라는걸 감안한다면 굉장히 선구적인 연구라고 볼 수 있습니다.